호텔 예약 취소 예측 AI 연습(예제)
2026. 1. 16. 16:28ㆍAI활용 멀티모달&MCP 과정
호텔 예약 취소 예측 AI 연습(예제)
- 학습 목표
- 호텔 예약 수요 데이터셋 소개
- 데이터셋 컬럼 설명
- 데이터 전처리 및 EDA
- 파생변수 생성
- 범주형 데이터 처리
- Logistic Regression 모델
- 데이터 스케일링
- 모델 학습 및 평가
- 오늘 공부한 내용 요약
학습 목표
이번 학습의 목표는 호텔 예약 정보 데이터를 기반으로 고객이 예약을 취소할지 여부를 예측하는 이진 분류 AI 모델을 만드는 것입니다. 이를 위해 다음과 같은 과정을 거칩니다.
- 호텔 예약 데이터 구조 이해
- EDA(탐색적 데이터 분석)를 통한 데이터 특성 파악
- 결측치 및 이상치 처리
- 머신러닝 학습을 위한 데이터 전처리
- Logistic Regression 모델 학습 및 평가
호텔 예약 수요 데이터셋 소개
이번 프로젝트에서는 Kaggle에서 제공하는 Hotel Booking Demand Dataset을 사용합니다.
이 데이터셋은 호텔 예약 정보와 고객 행동 데이터를 포함하고 있으며, 예약 취소 여부(is_canceled)를 예측하는 데 적합한 구조를 가지고 있습니다.
주요 활용 목적은 다음과 같습니다.
- 호텔 예약 취소 패턴 분석
- 고객 행동 예측
- 수요 예측 및 운영 전략 수립
데이터셋 컬럼 설명
- hotel: 호텔 유형 (Resort Hotel, City Hotel)
- is_canceled: 예약 취소 여부 (0: 유지, 1: 취소)
- lead_time: 예약과 체크인 사이의 기간(일)
- arrival_date_year: 도착 연도
- arrival_date_month: 도착 월
- arrival_date_week_number: 도착 주차
- arrival_date_day_of_month: 도착 일
- stays_in_weekend_nights: 주말 숙박일 수
- stays_in_week_nights: 주중 숙박일 수
- adults / children / babies: 인원 수
- distribution_channel: 예약 채널
- adr: 평균 일일 요금
데이터 전처리 및 EDA
데이터 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# CSV 파일을 불러와 데이터프레임 생성
hotel_df = pd.read_csv('/본인의 구글드라이브 경로/hotel_bookings.csv')
hotel_df
기본 정보 확인
hotel_df.info()
# 컬럼 타입, 결측치 여부 확인
hotel_df.describe()
# 숫자형 데이터의 통계 정보 확인
lead_time 이상치 탐색
sns.displot(hotel_df['lead_time'])
# 예약 리드타임 분포 확인

sns.boxplot(hotel_df['lead_time'])
# 박스플롯을 통해 이상치 시각화
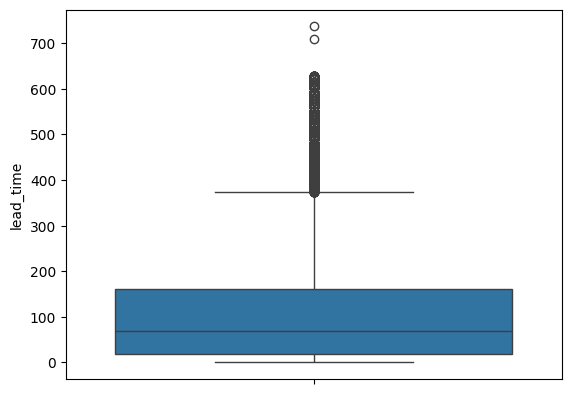
IQR 방식으로 이상치 제거
Q1 = hotel_df['lead_time'].quantile(0.25)
Q3 = hotel_df['lead_time'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 이상치 범위 밖 데이터 제거
hotel_df = hotel_df[(hotel_df['lead_time'] >= lower_bound) & (hotel_df['lead_time'] <= upper_bound)]

파생변수 생성
투숙 인원 수 파생변수
# adults, children, babies를 합쳐 people 변수 생성
hotel_df['people'] = hotel_df['adults'] + hotel_df['children'] + hotel_df['babies']
# 사람이 0명인 비정상 데이터 제거
hotel_df.drop(hotel_df[hotel_df['people'] == 0].index, inplace=True)
# 각 컬럼당 Null값 개수
hotel_df.isna().sum()
# 아이가 NaN인 데이터가 4개 있으므로 fillna(0)로 채워줌 수가 적으니까
hotel_df['children'] = hotel_df['children'].fillna(0)
# 하지만 어른이 한명도 없이 호텔 투숙하는 경우는 전처리 해야함
hotel_df[hotel_df['adults'] == 0]
# people 파생변수
hotel_df['people'] = hotel_df['adults'] + hotel_df['children'] + hotel_df['babies']
hotel_df.head()
# 어른이 '0'인 데이터 drop으로 삭제
hotel_df.drop(hotel_df[hotel_df['people'] == 0].index, inplace=True)숙박일 수 파생변수
hotel_df['total_nights'] = hotel_df['stays_in_week_nights'] + hotel_df['stays_in_weekend_nights']
# 파생변수를 생성했으니 주말 호텔 숙박, 평일 호텔 숙박 데이터 삭제
hotel_df.drop(['stays_in_week_nights', 'stays_in_weekend_nights'], axis=1, inplace=True)계절 파생변수
import calendar
season_dic = {'spring':[3,4,5], 'summer':[6,7,8], 'fall':[9,10,11], 'winter':[12,1,2]}
new_season_dic = {}
for i in season_dic:
for j in season_dic[i]:
new_season_dic[calendar.month_name[j]] = i
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)
# 월(month) 값을 계절(season) 값으로 바꿔서 새 컬럼을 만든다
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)
hotel_df[hotel_df['cancel_rate'].isna()] # cancel_rate 컬럼이 NaN인 행들만 골라서 보여준다
hotel_df.head()
hotel_df['agent'].value_counts(dropna=False).sort_index() # 👉 NaN(결측값)을 집계에서 버릴지 말지 정하는 옵션범주형 데이터 처리
# 범주형 컬럼 원-핫 인코딩
hotel_df = pd.get_dummies(
hotel_df,
columns=hotel_df.select_dtypes(exclude=['number']).columns.tolist(),
drop_first=True
)
from sklearn.model_selection import train_test_split # 사이킷런(sklearn)
# is_canceled를 정답(y)으로 두고,
# 나머지 컬럼을 입력 데이터(X)로 사용하여
# 전체 데이터를 학습용 70%, 테스트용 30%로 랜덤 분할
X_train, X_test, y_train, y_test = train_test_split(
hotel_df.drop('is_canceled', axis=1),
hotel_df['is_canceled'],
test_size=0.3,
random_state=2025
)
# 숫자형 컬럼을 제외한 범주형(문자) 컬럼들을
# 원-핫 인코딩하여 모두 숫자 컬럼으로 변환
hotel_df = pd.get_dummies(
hotel_df,
columns=hotel_df.select_dtypes(exclude=['number']).columns.tolist(),
drop_first=True
)
hotel_df.head()Logistic Regression 모델
Logistic Regression은 확률 기반 이진 분류 모델로, 예약 취소 여부 예측에 적합한 알고리즘입니다.
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(max_iter=1000)
lr.fit(X_train, y_train)
데이터 스케일링
Logistic Regression은 거리 기반 최적화를 사용하므로 스케일링이 필수입니다.
from sklearn.preprocessing import StandardScaler # 각 컬럼을 평균 0, 표준편차 1로 맞춤
scaler = StandardScaler()
# # 학습 데이터 기준으로 평균과 표준편차를 계산하고 변환
x_train_scaled = scaler.fit_transform(X_train)
x_test_scaled = scaler.transform(X_test)
x_train_scaled
# 0 근처 → 평균에 가까운 값
# 음수 → 평균보다 작은 값
# 양수 → 평균보다 큰 값
모델 학습 및 평가
model = LogisticRegression(max_iter=1000)# max_iter 모델이 최적의 답을 찾기 위해 “반복해서 계산하는 최대 횟수
model.fit(x_train_scaled, y_train)
pred = model.predict(x_test_scaled)from sklearn.metrics import accuracy_score # 모델의 예측값과 실제값을 비교해 정확도를 계산하는 함수
# 테스트 데이터의 실제 정답(y_test)과
# 모델이 예측한 값(pred)을 비교하여 정확도(accuracy)를 계산
accuracy_score(y_test, pred)
# 원본 데이터프레임에서
# 실제 취소 여부(is_canceled)의 값 분포(0, 1 개수)를 확인
hotel_df['is_canceled'].value_counts()
accuracy_score(y_test, pred) -> 결과 1.0 호텔예약을 취소할지 예측을 너무 잘함 100퍼센트임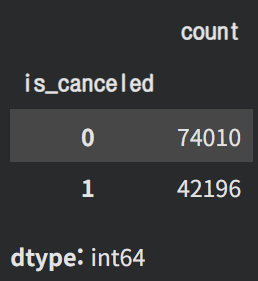
오늘 공부한 내용 요약
- EDA를 통해 데이터 분포와 이상치를 파악
- IQR 방식으로 lead_time 이상치 제거
- people, total_nights, season 파생변수 생성
- 원-핫 인코딩으로 범주형 데이터 처리
- StandardScaler로 데이터 표준화
- Logistic Regression으로 예약 취소 예측
| 명령어 / 함수 | 설명 | 주요 옵션/인자 |
|---|---|---|
pd.read_csv() |
CSV 파일을 데이터프레임으로 불러옴 | 파일 경로 |
StandardScaler |
데이터를 평균 0, 표준편차 1로 변환 | fit, transform |
LogisticRegression |
이진 분류 모델 | max_iter |
```
'AI활용 멀티모달&MCP 과정' 카테고리의 다른 글
| 서울 자전거 공유(따릉이) 수요 데이터 분석 및 예측 (0) | 2026.01.07 |
|---|---|
| 주택 임대료 데이터셋으로 Rent비 예측하는 AI 만들기 (1) | 2026.01.06 |
| 사이킷런의 SVC(Support Vector Classifier)를 활용한 Iris 데이터셋 분류 (0) | 2025.12.22 |
| House Rent Prediction 데이터셋 분석과 회귀 모델링 (0) | 2025.12.22 |
| Git 기초부터 GitHub 협업까지 완벽 정리 (0) | 2025.12.10 |