2025. 12. 22. 15:42ㆍAI활용 멀티모달&MCP 과정
사이킷런의 SVC(Support Vector Classifier)를 활용한 Iris 데이터셋 분류
학습 목표
이번 내용에서는 Support Vector Machine(SVM)의 기본 개념을 이해하고, 사이킷런의 SVC 클래스를 사용해 Iris 데이터셋의 붓꽃 품종을 분류하는 전체 과정을 실습합니다. SVM이 클래스 간 최적의 경계를 찾는 원리를 파악하고, 데이터 로드부터 전처리, 학습/테스트 분리, 모델 학습, 예측 및 평가까지 사이킷런의 표준 흐름을 익히는 것이 목적입니다. 주요 함수로는 load_iris, train_test_split(stratify 옵션 포함), SVC, accuracy_score 등을 활용합니다.
목차
- 1. Support Vector Classifier(SVC)와 SVM 소개
- 2. Iris 데이터셋 소개
- 3. 데이터 로드 및 탐색
- 4. 학습/테스트 데이터 분리와 stratify의 중요성
- 5. SVC 모델 학습 및 예측
- 6. 모델 평가와 새로운 데이터 예측
1. Support Vector Classifier(SVC)와 SVM 소개
SVC는 Support Vector Machine(SVM)을 기반으로 한 분류 알고리즘으로, 사이킷런의 sklearn.svm.SVC에서 제공됩니다. SVM은 클래스 간 경계를 구분하는 초평면(hyperplane)을 찾되, 서로 다른 클래스에 가장 가까운 데이터 포인트(서포트 벡터)까지의 거리인 마진(margin)을 최대화하는 방향으로 최적의 경계를 결정합니다. 이 방식은 데이터의 일반화 성능을 높여주며, 특히 작은 데이터셋에서 강력한 성능을 보입니다.
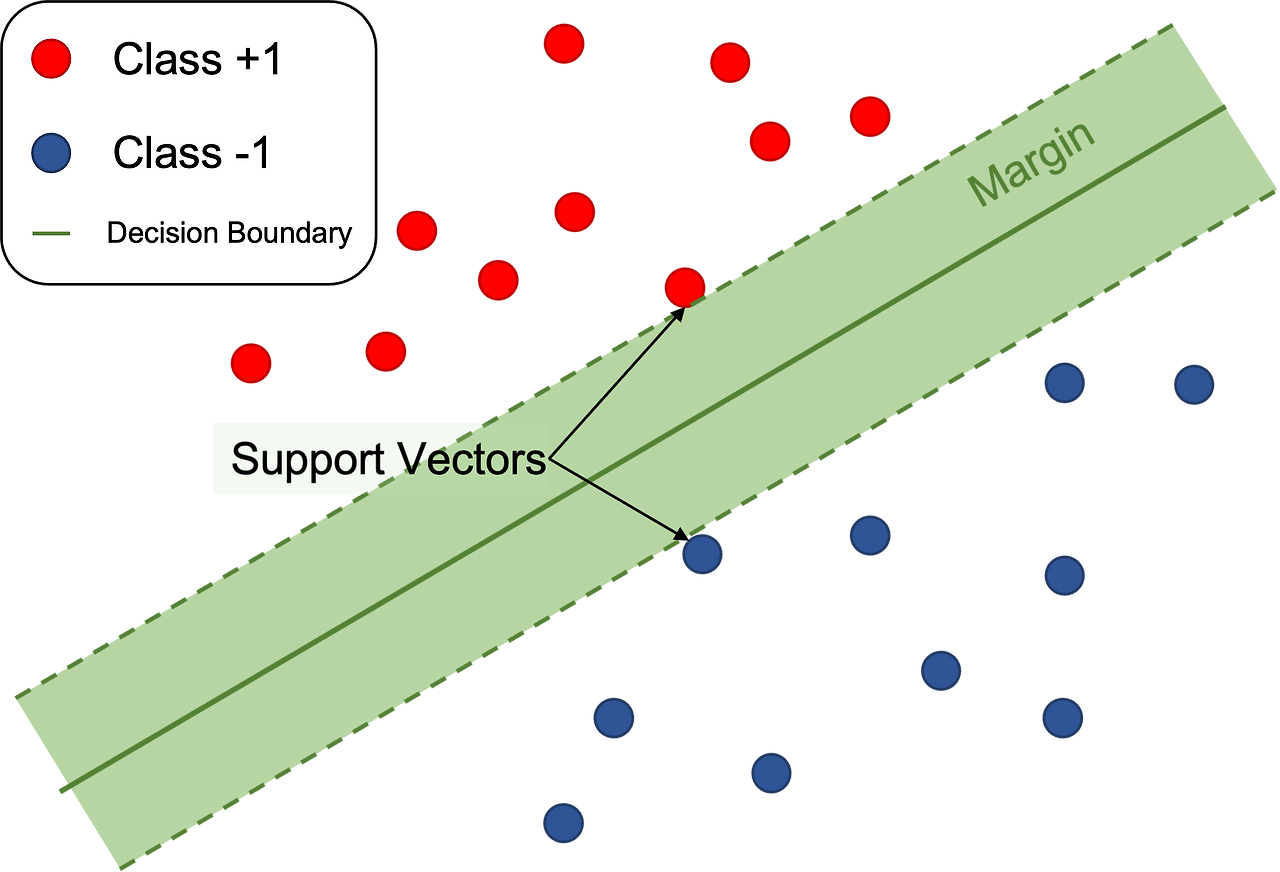
2. Iris 데이터셋 소개
Iris 데이터셋은 세 가지 붓꽃 품종(Setosa=0, Versicolor=1, Virginica=2)을 4개의 특성(꽃받침 길이/너비, 꽃잎 길이/너비)으로 분류하는 고전적인 데이터셋입니다. 총 150개 샘플(품종당 50개)이 균등하게 분포되어 있어 다중 클래스 분류 연습에 이상적입니다.
실제 붓꽃 품종 비교:
특히 꽃잎 길이와 너비를 기준으로 보면 품종 간 구분이 뚜렷하게 나타납니다.
3. 데이터 로드 및 탐색
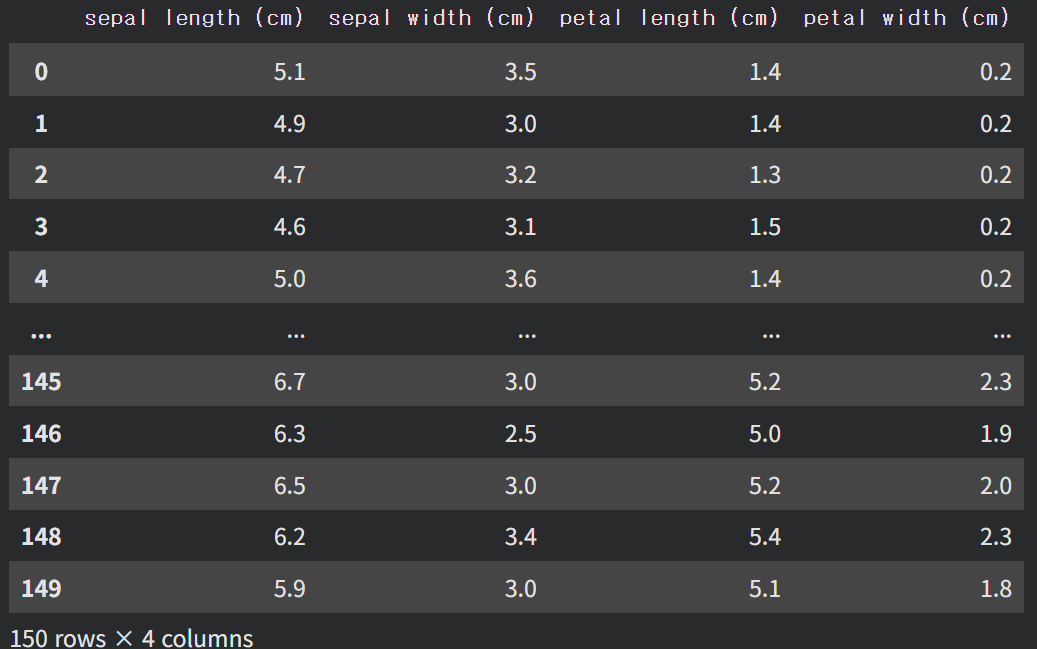
사이킷런 내장 데이터셋을 불러와 Pandas DataFrame으로 변환합니다.
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
data = iris['data']
feature_names = iris['feature_names']
df_iris = pd.DataFrame(data, columns=feature_names)
df_iris['m_target'] = iris['target']
df_iris.head() # 상위 데이터 확인
4. 학습/테스트 데이터 분리와 stratify의 중요성
데이터를 학습용과 테스트용으로 분리할 때 단순 random 분리는 클래스 비율이 깨질 수 있습니다. stratify 옵션을 사용하면 원본 데이터의 클래스 비율을 유지합니다.
X_train : 학습시 문제
X_test : 테스트시 문제
y_train : 학습시 정답
y_test : 테스트시 정답
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# stratify 없이 분리 (비율 깨짐 예시)
X_train, X_test, y_train, y_test = train_test_split(
df_iris.drop('m_target', axis=1),
df_iris['m_target'],
test_size=0.2, random_state=2025
)
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
y_train.value_counts().sort_index().plot(kind='bar', ax=axes[0], title='y_train (No Stratify)')
y_test.value_counts().sort_index().plot(kind='bar', ax=axes[1], title='y_test (No Stratify)')

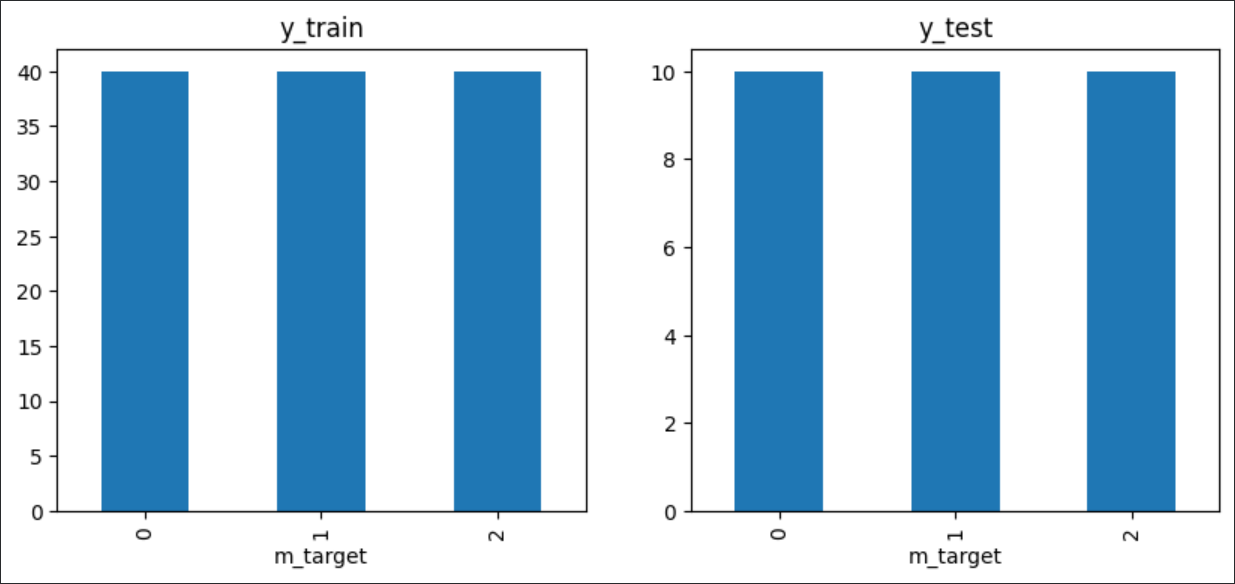
# stratify 적용 (비율 유지)
X_train, X_test, y_train, y_test = train_test_split(
df_iris.drop('m_target', axis=1),
df_iris['m_target'],
test_size=0.2, random_state=2026, stratify=df_iris['m_target']
)
X_train.shape, X_test.shape # ((120, 4), (30, 4))
5. SVC 모델 학습 및 예측
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
svc = SVC() # 기본 설정 (RBF 커널 등)
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
y_pred
6. 모델 평가와 새로운 데이터 예측
print('정답률', accuracy_score(y_test, y_pred))
# 출력 예시: 정답률 0.9666666666666667
# 새로운 데이터 예측
new_data = pd.DataFrame([[6.2, 3.0, 5.1, 2.5]],
columns=feature_names)
svc.predict(new_data) # array([2]) → Virginica
Iris처럼 선형적으로 잘 구분되는 데이터에서는 SVC가 높은 정확도를 보입니다.
오늘 공부한 내용 요약
- SVM은 마진 최대화를 통해 최적의 클래스 구분 초평면을 찾습니다.
- Iris 데이터셋은 3개 품종을 4개 특성으로 분류하는 대표적인 예제입니다.
- train_test_split에서
stratify를 사용하면 클래스 비율을 유지해 안정적인 평가가 가능합니다. - 사이킷런 SVC는 간단히
fit과predict로 학습/예측을 수행합니다. - 기본 설정만으로도 Iris 데이터에서 96% 이상의 정확도를 달성할 수 있습니다.
이 실습을 통해 SVM의 직관적 원리와 사이킷런의 실전 활용 방법을 이해할 수 있었습니다.
| 명령어 / 함수 | 설명 | 주요 옵션/인자 |
|---|---|---|
load_iris() |
Iris 데이터셋 로드 | 없음 (Bunch 객체 반환) |
train_test_split() |
데이터를 학습/테스트로 분리 | test_size, random_state, stratify |
SVC() |
SVM 기반 분류 모델 생성 | C (규제), kernel ('linear', 'rbf' 등) |
model.fit(X, y) |
모델 학습 | X: 특성 행렬, y: 타겟 벡터 |
model.predict(X) |
새 데이터 예측 | X: 예측할 특성 데이터 |
accuracy_score(y_true, y_pred) |
분류 정확도 측정 | y_true: 실제값, y_pred: 예측값 |
'AI활용 멀티모달&MCP 과정' 카테고리의 다른 글
| 서울 자전거 공유(따릉이) 수요 데이터 분석 및 예측 (0) | 2026.01.07 |
|---|---|
| 주택 임대료 데이터셋으로 Rent비 예측하는 AI 만들기 (1) | 2026.01.06 |
| House Rent Prediction 데이터셋 분석과 회귀 모델링 (0) | 2025.12.22 |
| Git 기초부터 GitHub 협업까지 완벽 정리 (0) | 2025.12.10 |
| 스타벅스와 경쟁 커피숍의 입지 전략 분석 (0) | 2025.12.08 |