2025. 12. 22. 10:47ㆍAI활용 멀티모달&MCP 과정
House Rent Prediction 데이터셋 분석과 회귀 모델링
학습 목표
이번 글에서는 House Rent Prediction 데이터셋을 활용해 주택 임대료를 예측하는 과정을 살펴봅니다. 데이터셋의 구조와 컬럼을 이해한 후, 전처리와 탐색적 데이터 분석(EDA)을 수행하고, Boxplot으로 이상치를 파악합니다. 이후 선형 회귀 모델을 기반으로 학습하고, 이상치 처리, 로그 변환, 앙상블 모델(Random Forest, XGBoost) 적용을 통해 성능을 개선하는 방법을 배웁니다. 이를 위해 pandas, seaborn, sklearn.linear_model.LinearRegression, sklearn.ensemble.RandomForestRegressor, xgboost.XGBRegressor, sklearn.metrics.mean_squared_error와 root_mean_squared_error, numpy.log1p/expm1 등의 라이브러리와 함수를 사용합니다.
- 1. 데이터셋 소개와 컬럼 설명
- 2. Boxplot 이해
- 3. 데이터 로드와 탐색적 분석(EDA)
- 4. 데이터 전처리
- 5. 데이터 분할과 선형 회귀 모델링
- 6. 이상치 처리 시도
- 7. 로그 변환을 통한 성능 개선
- 8. 앙상블 모델 적용 (Random Forest, XGBoost)
- 오늘 공부한 내용 요약
1. 데이터셋 소개와 컬럼 설명
House Rent Prediction Dataset(https://myip.kr/xvVKl)은 주택의 다양한 특성(BHK, Size, Floor 등)을 바탕으로 월 임대료(Rent)를 예측하는 데 사용됩니다. 주요 컬럼은 다음과 같습니다:
- BHK: 침실, 거실, 주방 개수 합
- Rent: 월 임대료 (타겟 변수)
- Size: 면적 (평방피트)
- Floor: 층수 정보
- Area Type: 면적 계산 방식
- Area Locality: 지역
- City: 도시
- Furnishing Status: 가구 상태
- Tenant Preferred: 선호 임차인 유형
- Bathroom: 욕실 개수
- Point of Contact: 연락 담당자
2. Boxplot 이해
Boxplot은 데이터 분포와 이상치를 시각적으로 확인하는 데 유용합니다.
- 중앙값 (Median, Q2): 정렬된 데이터의 중간 값
- Q1 (제1사분위수): 하위 25%
- Q3 (제3사분위수): 상위 25%
- IQR: Q3 - Q1 (중간 50% 범위)
- Minimum/Maximum: IQR ± 1.5 × IQR 범위 내 극값
- 이상치: 범위를 벗어난 값
IQR 기준은 일반적이지만 데이터에 따라 완벽하지 않을 수 있습니다.
예시

3. 데이터 로드와 탐색적 분석(EDA)
데이터를 불러온 후 기본 통계와 분포를 확인합니다.
import numpy as np
import pandas as pd
import seaborn as sns
rent_df = pd.read_csv('House_Rent_Dataset.csv')
rent_df.info()
rent_df.describe()
sns.displot(rent_df['Rent'])
sns.displot(rent_df['Size'])
sns.displot(rent_df['BHK'])
sns.boxplot(rent_df['Rent'])
sns.boxplot(rent_df['Size'])
sns.boxplot(rent_df['BHK'])
rent_df.isna().sum() # 결측치 확인
Rent와 Size 컬럼에서 오른쪽 치우침과 이상치가 관찰됩니다.
4. 데이터 전처리
불필요한 컬럼 제거와 원-핫 인코딩을 적용합니다.
rent_df.drop(['Floor', 'Area Locality', 'Posted On'], axis=1, inplace=True)
rent_df = pd.get_dummies(rent_df, columns=['Area Type', 'City', 'Furnishing Status', 'Tenant Preferred', 'Point of Contact'])
X = rent_df.drop('Rent', axis=1)
y = rent_df['Rent']
5. 데이터 분할과 선형 회귀 모델링
데이터를 훈련/테스트로 분할하고 선형 회귀를 적용합니다. 선형 회귀는 최소 제곱법(OLS)을 사용하며, 사이킷런에서는 SVD로 안정적으로 계산합니다.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, root_mean_squared_error
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2025)
lr = LinearRegression()
lr.fit(X_train, y_train)
pred = lr.predict(X_test)
print(mean_squared_error(y_test, pred))
print(root_mean_squared_error(y_test, pred))
초기 RMSE는 높은 수준으로 나타납니다.
6. 이상치 처리 시도
Boxplot으로 확인된 이상치(예: 고가 임대료)를 제거하고 재학습합니다.
X_train.drop(1837, inplace=True)
y_train.drop(1837, inplace=True)
lr = LinearRegression()
lr.fit(X_train, y_train)
new_pred = lr.predict(X_test)
root_mean_squared_error(y_test, new_pred)
이상치 제거 후 성능이 오히려 악화될 수 있으며, 이는 데이터의 비선형성을 시사합니다.
7. 로그 변환을 통한 성능 개선
Rent 분포가 오른쪽으로 치우쳐 있으므로 로그 변환을 적용해 정규 분포에 가깝게 만듭니다.
y_train = np.log1p(y_train)
y_test = np.log1p(y_test)
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred_log = lr.predict(X_test)
log_pred = np.expm1(y_pred_log)
y_test_original = np.expm1(y_test)
root_mean_squared_error(y_test_original, log_pred)
로그 변환은 큰 값의 영향을 줄여 RMSE를 크게 개선합니다.
8. 앙상블 모델 적용 (Random Forest, XGBoost)
비선형 관계를 잘 포착하는 앙상블 모델을 로그 변환된 데이터에 적용합니다.
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
models = {
'Linear Regression': LinearRegression(),
'Random Forest': RandomForestRegressor(n_estimators=100, random_state=2025),
'XGBoost': XGBRegressor(n_estimators=100, random_state=2025)
}
results = {}
for model_name, model in models.items():
model.fit(X_train, y_train)
y_pred_log = model.predict(X_test)
y_pred = np.expm1(y_pred_log)
y_test_original = np.expm1(y_test)
rmse = np.sqrt(mean_squared_error(y_test_original, y_pred))
results[model_name] = rmse
print(f'{model_name} RMSE: {rmse:.2f}')
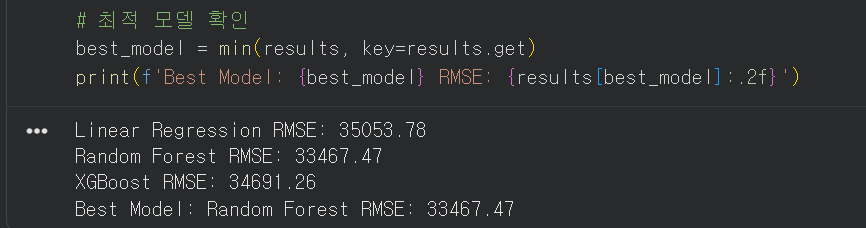
best_model = min(results, key=results.get)
print(f'Best Model: {best_model} RMSE: {results[best_model]:.2f}')
오늘 공부한 내용 요약
오늘은 House Rent Prediction 데이터셋을 통해 EDA부터 모델링까지 전체 과정을 살펴보았습니다. Boxplot으로 이상치를 확인하고, 선형 회귀의 한계를 넘어 로그 변환으로 분포를 개선하며 RMSE를 낮췄습니다. 마지막으로 Random Forest와 XGBoost 같은 앙상블 모델을 적용해 더 높은 예측 성능을 얻는 방법을 배웠습니다. 실제 프로젝트에서는 이러한 반복적인 전처리와 모델 비교가 핵심입니다.
| 명령어 / 함수 | 설명 | 주요 옵션/인자 |
|---|---|---|
pd.read_csv |
CSV 데이터 로드 | 파일 경로 |
sns.boxplot |
Boxplot 시각화 | 데이터 컬럼 |
pd.get_dummies |
원-핫 인코딩 | columns |
train_test_split |
데이터 분할 | test_size, random_state |
LinearRegression |
선형 회귀 모델 | fit, predict |
np.log1p / expm1 |
로그 변환 및 역변환 | 배열 |
RandomForestRegressor |
랜덤 포레스트 회귀 | n_estimators, random_state |
XGBRegressor |
XGBoost 회귀 | n_estimators, random_state |
root_mean_squared_error |
RMSE 계산 | y_true, y_pred |
'AI활용 멀티모달&MCP 과정' 카테고리의 다른 글
| 주택 임대료 데이터셋으로 Rent비 예측하는 AI 만들기 (1) | 2026.01.06 |
|---|---|
| 사이킷런의 SVC(Support Vector Classifier)를 활용한 Iris 데이터셋 분류 (0) | 2025.12.22 |
| Git 기초부터 GitHub 협업까지 완벽 정리 (0) | 2025.12.10 |
| 스타벅스와 경쟁 커피숍의 입지 전략 분석 (0) | 2025.12.08 |
| 소상공인 상가(상권)정보 데이터로 서울 지도 시각화하기 (0) | 2025.11.28 |