2026. 1. 7. 15:16ㆍAI활용 멀티모달&MCP 과정
서울 자전거 공유(따릉이) 수요 데이터 분석 및 예측
- 학습 목표
- 데이터셋 소개
- 데이터 컬럼 설명
- 데이터 전처리 및 EDA
- 파생 변수 및 인코딩
- 상관관계 분석과 다중공선성
- 모델링 (Decision Tree / Random Forest)
- 오늘 공부한 내용 요약
학습 목표
이 글의 목적은 서울시 공공자전거(따릉이) 대여 수요 데이터를 활용하여 데이터 분석의 전반적인 흐름을 이해하고, EDA → 전처리 → 특성 엔지니어링 → 모델 학습 → 성능 평가까지의 과정을 경험하는 것입니다.
- EDA를 통해 데이터의 구조와 특성을 파악한다.
- 날짜 및 범주형 변수를 모델이 학습할 수 있도록 변환한다.
- 상관관계와 다중공선성을 고려하여 변수를 정제한다.
- 결정 트리와 랜덤 포레스트 모델을 활용해 수요를 예측한다.
1. 서울 자전거 공유 수요 데이터셋
본 데이터셋은 서울시의 공공자전거 대여 서비스인 따릉이의 시간대별 대여 수요를 예측하기 위해 사용됩니다.
날씨, 시간, 계절, 휴일 여부 등 다양한 요인을 바탕으로 Rented Bike Count(대여 수)를 예측하는 회귀 문제입니다.
데이터 출처: Kaggle – Seoul Bike Sharing Demand Dataset
2. 데이터셋 컬럼
- Date : 연월일
- Rented Bike Count : 시간당 자전거 대여 수
- Hour : 하루 중 시간
- Temperature : 기온
- Humidity : 습도 (%)
- Wind speed : 풍속 (m/s)
- Visibility : 가시거리 (m)
- Dew point temperature : 이슬점 온도
- Solar Radiation : 태양 복사량 (MJ/m²)
- Rainfall : 강우량 (mm)
- Snowfall : 적설량 (cm)
- Seasons : 계절
- Holiday : 휴일 여부
- Functioning Day : 운영 여부
3. 데이터 전처리 및 탐색적 데이터 분석 (EDA)
라이브러리 로드 및 데이터 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
bike_df = pd.read_csv('/본인의 구글드라이브 경로/SeoulBikeData.csv', encoding='CP949')
bike_df
CP949는 Windows 환경에서 주로 사용되는 한국어 문자 인코딩으로, 한글이 깨지는 문제를 방지하기 위해 지정합니다.
데이터 구조 확인
bike_df.info()
bike_df.describe()
bike_df.columns
info()는 데이터 타입과 결측치 여부를, describe()는 수치형 데이터의 분포를 빠르게 파악하는 데 사용됩니다.
컬럼명 정리
bike_df.columns = ['Date', 'Rented Bike Count', 'Hour', 'Temperature', 'Humidity',
'Wind speed', 'Visibility', 'Dew point temperature',
'Solar Radiation', 'Rainfall', 'Snowfall', 'Seasons',
'Holiday', 'Functioning Day']
변수 간 관계 시각화
sns.scatterplot(x='Temperature', y='Rented Bike Count', data=bike_df, alpha=0.3)
온도가 높아질수록 대여 수가 증가하는 경향을 시각적으로 확인할 수 있습니다.
sns.scatterplot(x='Hour', y='Rented Bike Count', data=bike_df, alpha=0.3)
출퇴근 시간대에 수요가 집중되는 패턴이 관찰됩니다.
4. 날짜 처리 및 파생 변수 생성
bike_df['Date'] = pd.to_datetime(bike_df['Date'], format='%d/%m/%Y')
bike_df['year'] = bike_df['Date'].dt.year
bike_df['month'] = bike_df['Date'].dt.month
bike_df['day'] = bike_df['Date'].dt.day
날짜 데이터는 그대로 두기보다 연, 월, 일 단위로 분해하면 계절성이나 장기적인 패턴을 모델이 더 잘 학습할 수 있습니다.
시간대 범주화
bike_df['TimeOfDay'] = pd.cut(
bike_df['Hour'],
bins=[0, 5, 11, 17, 23],
labels=['Dawn', 'Morning', 'Afternoon', 'Evening'],
include_lowest=True
)
연속형 변수인 Hour를 의미 있는 시간대 범주로 변환하여 해석력과 모델 성능 향상을 기대할 수 있습니다.
5. 상관관계 분석 및 다중공선성
correlation_matrix = bike_df.corr()
target_corr = correlation_matrix['Rented Bike Count'].sort_values(ascending=False)
print(target_corr)
corr() 함수는 변수 간 선형 관계를 수치로 확인할 수 있으며, 상관관계가 지나치게 높은 변수들은 다중공선성 문제를 일으킬 수 있습니다.
상관관계 히트맵
plt.figure(figsize=(16, 12))
sns.heatmap(correlation_matrix, annot=True, fmt='.2f', cmap='coolwarm')
plt.show()
★ 이미지 삽입 위치 (상관관계 히트맵)
VIF 개념
VIF(Variance Inflation Factor)는 한 독립변수가 다른 독립변수들에 의해 얼마나 설명되는지를 나타내는 지표입니다.
- VIF < 5 : 문제 없음
- 5 ≤ VIF < 10 : 주의
- VIF ≥ 10 : 다중공선성 의심
6. 모델링
학습 / 테스트 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
bike_df.drop('Rented Bike Count', axis=1),
bike_df['Rented Bike Count'],
test_size=0.3,
random_state=2025
)
결정 트리 회귀
※ DecisionTreeRegressor
DecisionTreeRegressor는 주어진 데이터를 반복적으로 분할하여 예측을 수행합니다. 각 분할은 데이터의 목표 변수 값을 예측하는 데 가장 적합한 값을 찾기 위해 이루어집니다. 이를 통해 데이터를 점차 더 작은 부분으로 나누고, 각 부분에서 평균값을 예측값으로 사용하는 방식입니다. DecisionTreeRegressor 데이터를 두 가지 그룹으로 분할합니다. 각 분할에서 목표는 두 그룹의 MSE가 가능한 한 낮도록 만드는 것입니다. 즉, 각 분할에서의 MSE가 최소화되도록 분할점을 찾습니다.
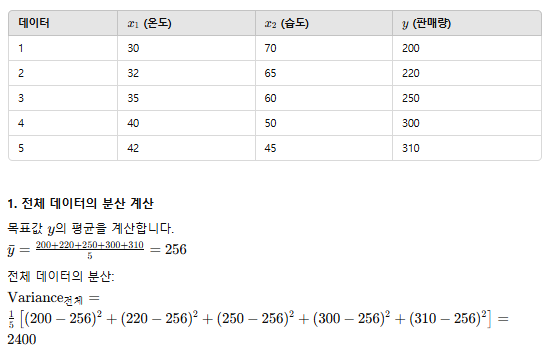


from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor(random_state=2025)
dtr.fit(X_train, y_train)
pred1 = dtr.predict(X_test)
결정 트리는 해석이 쉬운 대신 과적합이 발생하기 쉬워 하이퍼파라미터 조정이 중요합니다.
랜덤 포레스트
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(random_state=2025)
rf.fit(X_train, y_train)
pred4 = rf.predict(X_test)
랜덤 포레스트는 여러 개의 결정 트리를 결합한 앙상블 모델로, 일반적으로 단일 트리보다 안정적인 성능을 보입니다.
★ 이미지 삽입 위치 (특성 중요도 그래프)
오늘 공부한 내용 요약
- 서울 자전거 대여 데이터를 활용한 회귀 문제를 이해했다.
- EDA를 통해 변수 간 관계와 데이터 특성을 파악했다.
- 날짜 및 범주형 변수를 모델 학습이 가능하도록 변환했다.
- 상관관계와 다중공선성을 고려해 변수를 정제했다.
- 결정 트리와 랜덤 포레스트 모델의 특징과 차이를 확인했다.
| 명령어 / 함수 | 설명 | 주요 옵션/인자 |
|---|---|---|
pd.read_csv() |
CSV 파일을 DataFrame으로 불러오는 함수 | encoding, sep, path |
pd.to_datetime() |
문자열 형태의 날짜 데이터를 datetime 타입으로 변환 | format |
pd.get_dummies() |
범주형 변수를 원-핫 인코딩으로 변환 | columns, drop_first |
corr() |
수치형 변수 간 상관관계 계산 | Pearson (기본) |
DecisionTreeRegressor |
결정 트리 기반 회귀 모델 | max_depth, min_samples_leaf |
RandomForestRegressor |
여러 결정 트리를 결합한 앙상블 회귀 모델 | n_estimators, random_state |
'AI활용 멀티모달&MCP 과정' 카테고리의 다른 글
| 호텔 예약 취소 예측 AI 연습(예제) (0) | 2026.01.16 |
|---|---|
| 주택 임대료 데이터셋으로 Rent비 예측하는 AI 만들기 (1) | 2026.01.06 |
| 사이킷런의 SVC(Support Vector Classifier)를 활용한 Iris 데이터셋 분류 (0) | 2025.12.22 |
| House Rent Prediction 데이터셋 분석과 회귀 모델링 (0) | 2025.12.22 |
| Git 기초부터 GitHub 협업까지 완벽 정리 (0) | 2025.12.10 |