2025. 8. 14. 16:02ㆍ심화_인공지능 YOLO기반 부트캠프_일기(CNN)
목차
2. 훈련/검증 데이터 분리: Overfitting 방지
- 최종 목적: 주어진 x 값에 대해 y 값을 예측할 수 있는 모델을 만드는 것
- 학습 과정에서 모델은 y = 3x² + 2라는 2차 함수 관계를 데이터와 노이즈를 보고 자동으로 학습
- 즉, 모델이 입력과 출력 사이의 수학적 패턴을 추론하도록 하는 것이 목표입니다.
- 모델이 학습하는 것은 함수 자체(y = f(x))가 아니라, x에 대응하는 y 값
- 즉, x를 입력하면 y 값을 출력하도록 함수를 근사(approximate) 하는 것
- 결과적으로 모델이 학습한 함수가 실제로는 y ≈ 3x² + 2 형태를 따르게 됨
1. 데이터 생성: 2차 함수와 노이즈 추가
이번 실습에서는 모델이 학습할 샘플 데이터를 먼저 만들어보았습니다.
np.random.seed(42)
x_np = np.linspace(-5, 5, 200)
y_np = 3 * x_np**2 + 2 + np.random.normal(0, 5, size=x_np.shape)
- np.random.seed(42)
- 난수 생성 초기값(seed)을 고정
- 같은 코드를 여러 번 실행해도 항상 동일한 난수 결과를 얻음
- 재현 가능한 실험을 위해 사용
- x_np = np.linspace(-5, 5, 200)
- -5에서 5까지 균등 간격 200개 점 생성
- x 데이터: 입력 값
- y_np = 3 * x_np**2 + 2 + np.random.normal(0, 5, size=x_np.shape)
- y 값 생성: 2차 함수 y=3x2+2y = 3x^2 + 2
- np.random.normal(0, 5, size=x_np.shape) → 평균 0, 표준편차 5인 정규분포 노이즈 추가
- 즉, 실제 환경처럼 잡음(Noise)이 섞인 데이터 생성
여기서 잠깐!
텐서(Tensor) = 다차원 배열
- 0차원 → 스칼라 (예: 3)
- 1차원 → 벡터 (예: [1,2,3])
- 2차원 → 행렬 (예: [[1,2],[3,4]])
- 3차원 이상 → 다차원 배열 (예: 이미지, 영상 등)
PyTorch에서 텐서는 숫자를 저장하고, GPU/CPU에서 계산까지 할 수 있는 배열
- x는 (100, 2) → 2차원 텐서(100x2 배열)
- y는 (100,) → 1차원 텐서(100개의 값)
2. 훈련/검증 데이터 분리: Overfitting 방지
모델 학습을 위해 데이터를 훈련용과 검증용으로 나누었습니다.
x_train_np, x_val_np, y_train_np, y_val_np = train_test_split(
x_np, y_np, test_size=0.2, random_state=42
)
- train_test_split을 사용해 80%는 훈련용, 20%는 검증용으로 분리
- random_state=42로 난수를 고정 → 재현 가능한 데이터 분리
분리한 데이터를 PyTorch에서 학습할 수 있도록 텐서로 변환합니다.
x_train = torch.tensor(x_train_np, dtype=torch.float32).unsqueeze(1)
y_train = torch.tensor(y_train_np, dtype=torch.float32).unsqueeze(1)
x_val = torch.tensor(x_val_np, dtype=torch.float32).unsqueeze(1)
y_val = torch.tensor(y_val_np, dtype=torch.float32).unsqueeze(1)- dtype=torch.float32 → 모델 학습용 실수형 데이터
- .unsqueeze(1) → 1차원 데이터를 (샘플 수, 1) 형태로 변환
- PyTorch Linear 레이어 입력 차원 맞추기
💡 이렇게 나누면 모델 학습 중에 Overfitting 여부를 검증할 수 있고, 학습 과정의 안정성을 높일 수 있습니다.
3. 모델 정의: 다층 퍼셉트론(MLP) 구성
학습할 모델을 **PyTorch의 nn.Sequential**로 정의했습니다.
model = nn.Sequential(
nn.Linear(1, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 1)
)- nn.Linear: 완전연결(fully connected) 레이어
- 입력 1 → 은닉층 64 노드 → 출력 1
- nn.ReLU(): 비선형 활성화 함수
- 은닉층에서 각 노드에 적용
- 선형 연산만으로는 복잡한 관계 학습이 어렵기 때문에 비선형성을 추가
- 구조:
- 총 5개의 은닉층, 각 64개 노드
- 마지막 레이어는 출력 1 → 회귀 문제에서 y 값 예측
💡 이렇게 하면 단순 2차 함수부터 복잡한 비선형 관계까지 학습 가능한 다층 신경망이 완성됩니다.
4. 손실 함수와 옵티마이저 설정
여기서 잠깐!!!
- “손실 = 모델이 틀린 정도”
- 학습 목표는 손실을 최소화하는 것 = “예측값을 정답에 최대한 가깝게 만드는 것”
모델 학습을 위해 **손실 함수(loss function)**와 **옵티마이저(optimizer)**를 정의했습니다.
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)- nn.MSELoss()
- MSE(Mean Squared Error, 평균 제곱 오차)
- 회귀 문제에서 모델 예측값과 실제값의 차이를 제곱하여 평균
- 값이 작을수록 모델이 실제 데이터를 잘 예측함
- optim.Adam
- Adam 최적화 알고리즘 사용
- 학습률(lr=0.01)로 가중치 업데이트 속도 조절
- Gradient Descent 기반의 빠르고 안정적인 학습 가능
💡 요약:
- 손실 함수 → 모델 학습 목표(얼마나 틀렸는지)
- 옵티마이저 → 목표를 향해 가중치를 업데이트하는 방법, 학습속도를 조절
이렇게 설정하면 모델이 예측값과 실제값 차이를 최소화하도록 학습하게 됩니다.
5. 모델 학습: Epoch 반복과 손실 기록
들어가기 전에 잠깐!!!
- 가중치 = model 안의 모든 weight와 bias 파라미터
- 그래디언트 = 이 가중치를 얼마나, 어떤 방향으로 바꿔야 하는지 알려주는 값(.grad)
모델을 학습시키기 위해 10,000번(epoch) 반복하면서 훈련 손실과 검증 손실을 기록합니다.
epochs = 10000
train_losses = []
val_losses = []train_losses와 val_losses → 학습 중 손실 변화를 저장
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
y_pred = model(x_train)
loss = criterion(y_pred, y_train)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
- model.train() → 학습 모드 활성화
- optimizer.zero_grad() → 이전 그래디언트 초기화
- loss.backward() → 손실 함수 기준으로 그래디언트 계산
- optimizer.step() → 계산된 그래디언트를 보고 가중치를 실제로 업데이트
# 검증 손실 계산
model.eval()
with torch.no_grad():
val_pred = model(x_val)
val_loss = criterion(val_pred, y_val)
val_losses.append(val_loss.item())
- with torch.no_grad(): → “여기 안에서는 그래디언트 계산 안 하고, 메모리와 속도 효율 높이겠다”
- model.eval() → 평가 모드
- torch.no_grad() → 검증 시 그래디언트 계산하지 않음 → 메모리 절약
- 검증 데이터로 손실 계산 → Overfitting 여부 확인
if epoch % 50 == 0:
print(f"Epoch {epoch}: Train Loss = {loss.item():.4f}, Val Loss = {val_loss.item():.4f}")
- 50 epoch마다 학습/검증 손실 출력 → 학습 추적
💡 요약:
- 훈련 손실: 모델이 훈련 데이터에 얼마나 잘 맞는지
- 검증 손실: 모델이 새로운 데이터에 얼마나 잘 일반화되는지
- 두 손실을 비교하면 Overfitting 여부 확인 가능

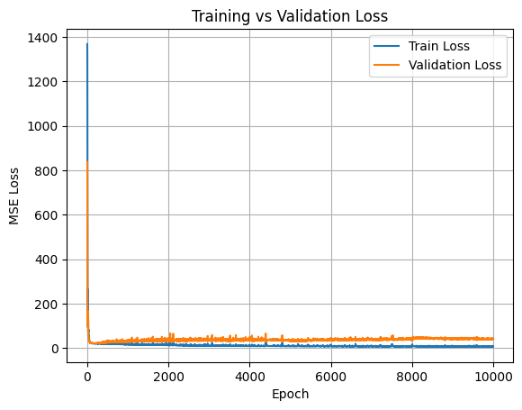
6. 손실 시각화: 학습과 검증 비교
학습이 잘 되고 있는지, 또는 **과적합(Overfitting)**이 발생하는지 확인하기 위해 **훈련 손실(train_losses)**과 **검증 손실(val_losses)**을 그래프로 그립니다.
plt.plot(train_losses, label="Train Loss")
plt.plot(val_losses, label="Validation Loss")
plt.title("Training vs Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.legend()
plt.grid()
plt.show()- X축: 학습 반복 횟수(epoch)
- Y축: 손실(MSE Loss)
- Train Loss: 모델이 훈련 데이터에서 얼마나 잘 맞는지
- Validation Loss: 모델이 새로운 데이터에서 얼마나 일반화되는지
Overfitting 감지
- 훈련 손실은 계속 감소하지만
- 검증 손실이 일정 시점 이후 증가 → 모델이 훈련 데이터에만 맞춰지고 새로운 데이터에는 약함 → 과적합 발생
💡 요약:
- 그래프를 통해 학습 상태를 직관적으로 확인
- 손실이 너무 큰 차이를 보이면 학습률 조절, 레이어 수정, 정규화 등 조치 필요
7. 모델 저장과 로드, 예측 시각화
모델 저장
torch.save(model.state_dict(), "quadratic_model.pth")
- state_dict() → 모델의 모든 가중치와 편향 저장
- 파일로 저장하면 나중에 학습 없이도 같은 모델 구조로 불러와 예측 가능
모델 로드
loaded_model = nn.Sequential(
nn.Linear(1, 64), nn.ReLU(),
nn.Linear(64, 64), nn.ReLU(),
nn.Linear(64, 64), nn.ReLU(),
nn.Linear(64, 64), nn.ReLU(),
nn.Linear(64, 64), nn.ReLU(),
nn.Linear(64, 1)
)
loaded_model.load_state_dict(torch.load("quadratic_model.pth"))
loaded_model.eval()
- 모델 구조를 동일하게 정의한 후
- load_state_dict()로 저장한 가중치 불러오기
- eval() → 추론 모드로 전환, 드롭아웃/배치정규화 등 학습용 기능 비활성화
예측시각화
with torch.no_grad():
y_test_pred = loaded_model(x_test).squeeze().numpy()
plt.scatter(x_np, y_np, label='Original Data', alpha=0.6)
plt.plot(x_test.squeeze().numpy(), y_test_pred, color='red', label='Model Prediction')
plt.show()- 새로운 입력 x_test에 대해 모델 예측 수행
- 원래 데이터와 모델 예측 결과를 그래프로 비교
- 빨간 선이 모델이 학습한 함수(예: y ≈ 3x² + 2)

💡 요약
- 학습 후 모델을 저장 → 나중에 재사용 가능
- 로드 후 예측 → 모델 성능 확인
- 시각화 → 데이터와 모델 예측 비교, 직관적 확인 가능
8. 전체 코드
# 1. 라이브러리 임포트
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
# 2. 데이터 생성
np.random.seed(42)
x_np = np.linspace(-5, 5, 200)
y_np = 3 * x_np**2 + 2 + np.random.normal(0, 5, size=x_np.shape)
# 3. 훈련/검증 데이터 분리 (Overfitting 감지를 위해)
x_train_np, x_val_np, y_train_np, y_val_np = train_test_split(x_np, y_np, test_size=0.2, random_state=42)
x_train = torch.tensor(x_train_np, dtype=torch.float32).unsqueeze(1)
y_train = torch.tensor(y_train_np, dtype=torch.float32).unsqueeze(1)
x_val = torch.tensor(x_val_np, dtype=torch.float32).unsqueeze(1)
y_val = torch.tensor(y_val_np, dtype=torch.float32).unsqueeze(1)
# 4. 모델 정의
model = nn.Sequential(
nn.Linear(1, 64),
nn.ReLU(), # 위의 레이어에 포함된 각 노드에 연결됨
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
# 5. 손실 함수, 옵티마이저
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 6. 학습
epochs = 10000
train_losses = []
val_losses = []
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
y_pred = model(x_train)
loss = criterion(y_pred, y_train)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
# 검증 손실 계산
model.eval()
with torch.no_grad():
val_pred = model(x_val)
val_loss = criterion(val_pred, y_val)
val_losses.append(val_loss.item())
if epoch % 50 == 0:
print(f"Epoch {epoch}: Train Loss = {loss.item():.4f}, Val Loss = {val_loss.item():.4f}")
# 7. Loss 시각화 (Overfitting 감지)
plt.plot(train_losses, label="Train Loss")
plt.plot(val_losses, label="Validation Loss")
plt.title("Training vs Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.legend()
plt.grid()
plt.show()
# 8. 모델 저장
torch.save(model.state_dict(), "quadratic_model.pth")
print(" 모델이 'quadratic_model.pth'로 저장되었습니다.")
# 9. 모델 새로 로드
loaded_model = nn.Sequential(
nn.Linear(1, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
loaded_model.load_state_dict(torch.load("quadratic_model.pth"))
loaded_model.eval()
print(" 저장된 모델을 성공적으로 로드했습니다.")
# 10. 예측 시각화
x_test = torch.linspace(-5, 5, 100).unsqueeze(1) # 2번째 차원 추가
with torch.no_grad():
y_test_pred = loaded_model(x_test).squeeze().numpy()
plt.scatter(x_np, y_np, label='Original Data', alpha=0.6)
plt.plot(x_test.squeeze().numpy(), y_test_pred, color='red', label='Model Prediction')
plt.title("Model Fit to Quadratic Data")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid()
plt.show()
# 11. 모델 사용 예제
x_input = torch.tensor([[4.0]])
with torch.no_grad():
y_output = loaded_model(x_input)
print(f" Predicted y for x=4.0: {y_output.item():.4f}")
1️⃣ 가중치(Weight)와 편향(Bias)
- 가중치(W): 입력 데이터가 결과에 얼마나 영향을 주는지 결정하는 숫자.
예: y = 3x1 + 2x2 + 1 → 여기서 3, 2가 가중치. - 편향(b): 직선(또는 함수)을 y축에서 얼마나 위/아래로 이동시킬지 결정하는 값.
예: +1이 편향.
👉 즉, W는 기울기, b는 y절편이라고 이해하면 돼요.
2️⃣ 선형 회귀 모델
- 규칙성이 있는 분산 데이터를 직선(또는 초평면)으로 근사해서 추론하는 모델.
- 2차원에서는 직선, 3차원에서는 평면, 더 많은 차원에서는 초평면.
👉 예를 들어, 공부시간(x)과 시험점수(y)의 관계가 "비슷하게 직선"을 그린다면 → 선형 회귀로 학습 가능.
3️⃣ 손실 함수
- 손실 함수(Loss Function): 모델이 예측한 값과 실제 값의 차이를 수치로 표현.
- 선형 회귀에서는 보통 **MSE (평균 제곱 오차)**를 사용 → (예측 - 실제)^2의 평균.
👉 Loss가 작을수록 예측이 실제에 가깝다는 뜻.
4️⃣ 옵티마이저와 역전파
- 역전파(Backpropagation):
모델이 낸 오차(Loss)를 바탕으로, 가중치와 편향을 얼마나 수정해야 할지 계산하는 과정.
쉽게 말하면 “잘못된 방향으로 간 만큼 되돌아오기” 과정. - 옵티마이저(Optimizer):
역전파로 계산된 기울기를 가지고 실제로 가중치와 편향을 업데이트하는 알고리즘.
(SGD, Adam, RMSProp 등 여러 방식이 있음)
👉 정리하면:
- 손실 함수가 "오차 크기"를 알려주고,
- 역전파가 "어느 방향으로 바꿔야 할지" 알려주고,
- 옵티마이저가 "얼마나 바꿀지" 실행하는 역할.
'심화_인공지능 YOLO기반 부트캠프_일기(CNN)' 카테고리의 다른 글
| PyTorch로 이진 분류와 선형 회귀 구현하기: 초보자 가이드 (0) | 2025.09.14 |
|---|---|
| 머신러닝 입문: PyTorch로 선형 데이터 예측해보기 (16) | 2025.08.18 |
| Pandas : 데이터프레임 기초부터 병합·결측치 처리·시각화까지 (12) | 2025.08.13 |
| 파이썬 고급 문법 정리 — 예외 처리, 제너레이터, 데코레이터까지,__call__ 메서드, 가변인자 덧셈 (6) | 2025.08.12 |
| Python 클래스 기초 (2) (6) | 2025.07.30 |