2025. 8. 13. 16:32ㆍ심화_인공지능 YOLO기반 부트캠프_일기(CNN)
1. 목차 소개
- 2. 파이썬 Pandas 라이브러리 소개
- 3. 주요 특징
- 4. 데이터프레임 기본 개념과 생성
- 5. fillna() 함수란?
- 6. mean() 함수란?
- 7. Pandas로 결측치(NaN) 처리하기 – 평균값으로 대치하기
- 8. duplicated() 함수로 중복 행 확인하기
- 9. Pandas로 데이터프레임 병합과 조인하기
9.1. merge() — 공통 열 기준으로 병합하기
9.2. concat() — 데이터프레임 이어붙이기 (위아래 또는 옆으로)
9.3. join() — 인덱스를 기준으로 병합하기 - 10. Matplotlib으로 시계열 데이터 시각화하기
2. 파이썬 Pandas 라이브러리 소개
파이썬 Pandas는 데이터 분석과 조작에 특화된 라이브러리입니다. 데이터 과학이나 분석 작업을 할 때 매우 유용하게 쓰이는데요, 제가 부트캠프에서 배우면서 느낀 주요 특징들을 간단히 정리해봤습니다.
3. 주요 특징
- 데이터 구조
- Series: 1차원 데이터로, 인덱스를 가지고 있습니다.
- DataFrame: 2차원 표 형태의 데이터 구조로, 행과 열로 구성되어 있습니다.
- 다양한 데이터 입출력 지원
CSV, 엑셀, SQL 등 여러 형식의 파일을 쉽게 불러오고 저장할 수 있습니다. - 풍부한 데이터 처리 기능
결측치 처리, 필터링, 정렬, 그룹화, 병합 등 다양한 작업을 손쉽게 할 수 있습니다. - 통계 및 시각화 연동
기본적인 통계 함수들이 제공되며, matplotlib 같은 시각화 도구와도 잘 연동됩니다. - 빠른 처리 속도
내부적으로 C로 최적화되어 있어 대용량 데이터도 빠르게 처리할 수 있습니다.
4. 데이터프레임 기본 개념과 생성
Pandas의 기본 데이터 구조인 Series와 DataFrame을 만드는 간단한 예제입니다.
import pandas as pd
# Series 생성
s = pd.Series([10, 20, 30], index=['a', 'b', 'c'])
print(s)실행 결과
a 10
b 20
c 30
dtype: int64
다음은 데이터 프레임을 만드는 예제 입니다.
# DataFrame 생성
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Score': [85, 90, 95]
}
df = pd.DataFrame(data)
print(df)실행 결과
Name Age Score
0 Alice 25 85
1 Bob 30 90
2 Charlie 35 95
더 큰 단위로 만들어 보죠!
df_emp = pd.DataFrame({
'번호': [1001, 1002, 1003, 1004, 1005],
'이름': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'부서번호': [10, 20, 10, 30, 40],
'입사일': ['2023-01-15', '2023-02-20', '2023-03-10', '2023-04-05', '2023-05-12'],
'전화': ['123-456-7890', '987-654-3210', '555-123-4567', '111-222-3333', '444-2548-5412']
})
print(df_emp)구글 코랩에서 실행한 결과

5. fillna() 함수란?
fillna()는 Pandas에서 결측치(NaN)를 다른 값으로 채워 넣는 함수입니다.
예를 들어, 데이터에 빠진 값이 있을 때 특정 숫자나 계산된 값(평균, 중간값 등)으로 대체할 때 씁니다.
df['점수'] = df['점수'].fillna(0) # 결측치를 0으로 채움6. mean() 함수란?
mean()은 Pandas에서 해당 컬럼의 평균값을 계산하는 함수입니다.
숫자 데이터의 산술평균(전체 합을 개수로 나눈 값)을 쉽게 구할 수 있어요.
평균값 = df['점수'].mean()
7. Pandas로 결측치(NaN) 처리하기 – 평균값으로 대치하기
아래 예제는 점수 데이터 중에 결측치(NaN)가 있을 때, 해당 결측치를 점수의 평균값으로 채우는 방법입니다.
import pandas as pd
import numpy as np
df = pd.DataFrame({
'이름': ['홍길동', '김철수', '이영희'],
'점수': [90, np.nan, 85]
})
print(df)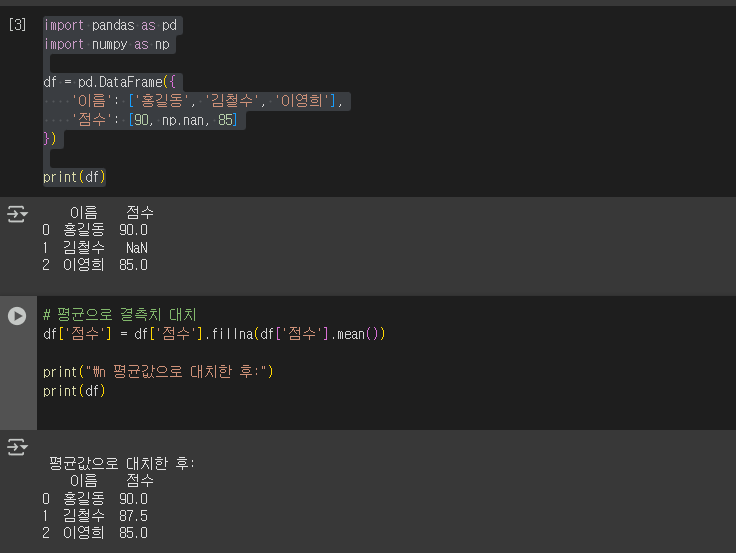
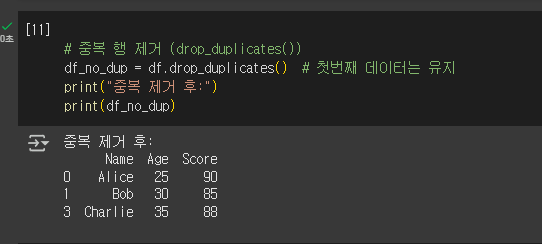
8. duplicated() 함수로 중복 행 확인하기
duplicated()는 DataFrame에서 중복된 행을 찾는 함수입니다.
모든 컬럼 값을 기준으로 이전에 나온 행과 같은 데이터가 있으면 True를 반환하고, 그렇지 않으면 False를 반환해요.

중복된 행은 분석에 방해가 될 수 있으니 보통 제거해 줍니다.
drop_duplicates() 함수는 첫 번째 등장하는 행은 유지하고, 이후 중복된 행들을 삭제해 줍니다.
간단히 중복 데이터를 정리할 때 아주 유용합니다.
drop_duplicates() 함수를 사용하면 중복을 제거할 수 있습니다.
9. Pandas로 데이터프레임 병합과 조인하기
데이터 분석할 때 여러 데이터프레임을 합치는 작업은 매우 자주 하게 됩니다.
Pandas에서는 merge(), concat(), join() 등 다양한 방법을 제공하는데요, 각각의 특징과 사용법을 예제와 함께 살펴보겠습니다.
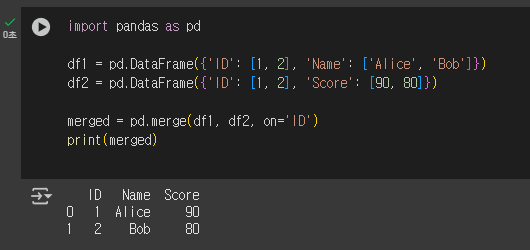
9.1. merge() — 공통 열 기준으로 병합하기
merge()는 SQL의 JOIN과 비슷하게, 특정 열을 기준으로 두 데이터프레임을 합칠 때 씁니다.
9.2. concat() — 데이터프레임 이어붙이기 (위아래 또는 옆으로)
concat()은 여러 데이터프레임을 단순히 이어 붙일 때 사용합니다.
인덱스가 중복되는 경우
df1 = pd.DataFrame({'Name': ['Alice', 'Bob'], 'Score': [90, 85]}, index=['s1', 's2'])
df2 = pd.DataFrame({'Name': ['Charlie', 'Bob'], 'Score': [88, 82]}, index=['s2', 's3'])
result = pd.concat([df1, df2])
print(result)

- 인덱스 s2가 중복되어 있어도 그대로 합칩니다.
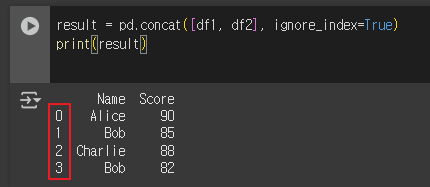
인덱스를 무시하고 합치기
result = pd.concat([df1, df2], ignore_index=True)
print(result)ignore_index=True로 새 인덱스를 0부터 자동 부여합니다.
중복된 인덱스 제거하기
result = pd.concat([df1, df2])
result = result[~result.index.duplicated(keep='first')]
print(result)
~result.index.duplicated(keep='first')는 중복된 인덱스 중 첫 번째만 남기고 제거합니다.
인덱스 재설정 후 합치기
df2_reset = df2.reset_index(drop=True)
result = pd.concat([df1, df2_reset], ignore_index=True)
print(result)
reset_index(drop=True)로 인덱스를 초기화해 충돌을 방지합니다.
9.3. join() — 인덱스를 기준으로 병합하기
join()은 기본적으로 인덱스를 기준으로 두 데이터프레임을 합칩니다.
df1 = pd.DataFrame({'이름': ['홍길동', '김철수', '이영희'], '수학': [90, 85, 88]}).set_index('이름')
df2 = pd.DataFrame({'이름': ['홍길동', '이영희', '박지민'], '영어': [95, 80, 75]}).set_index('이름')
result = df1.join(df2)
print(result)
- 기본 how='left' 옵션으로 왼쪽 데이터프레임의 인덱스를 모두 유지합니다.
다양한 join 방식
- how='inner' : 양쪽 모두에 존재하는 인덱스만 남김
- how='outer' : 모든 인덱스를 포함, 없는 값은 NaN
컬럼 이름 중복 처리
df3 = pd.DataFrame({'수학': [70, 60, 50]}, index=['홍길동', '김철수', '이영희'])
df1.join(df3, lsuffix='_왼쪽', rsuffix='_오른쪽')
같은 이름 컬럼이 충돌할 때 접미사를 붙여 구분할 수 있습니다.
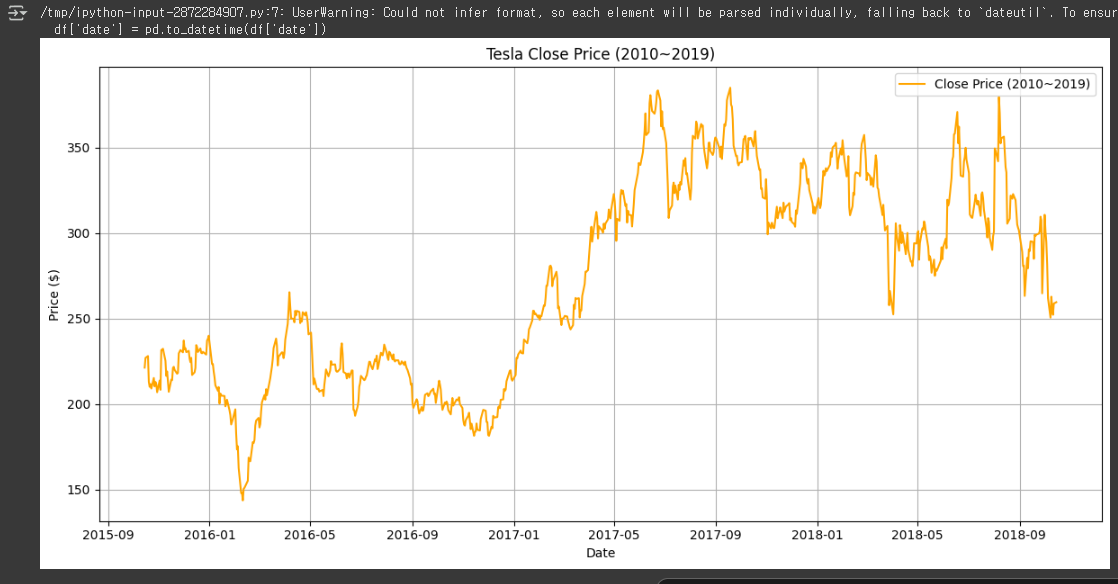
10. Matplotlib으로 시계열 데이터 시각화하기
.
import pandas as pd
import matplotlib.pyplot as plt
url = "https://raw.githubusercontent.com/plotly/datasets/master/tesla-stock-price.csv"
df = pd.read_csv(url)
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
df_early = df[df.index < '2020-01-01']
plt.figure(figsize=(12, 6))
plt.plot(df_early['close'], label='Close Price (2010~2019)', color='orange')
plt.title('Tesla Close Price (2010~2019)')
plt.xlabel('Date')
plt.ylabel('Price ($)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
- Tesla의 2010~2019년 종가(close) 변화를 시각화했습니다.
- date를 인덱스로 설정하고 matplotlib으로 간단하게 그래프를 그릴 수 있습니다.
'심화_인공지능 YOLO기반 부트캠프_일기(CNN)' 카테고리의 다른 글
| 머신러닝 입문: PyTorch로 선형 데이터 예측해보기 (16) | 2025.08.18 |
|---|---|
| 딥러닝 초보를 위한 PyTorch 모델 학습 기록 (14) | 2025.08.14 |
| 파이썬 고급 문법 정리 — 예외 처리, 제너레이터, 데코레이터까지,__call__ 메서드, 가변인자 덧셈 (6) | 2025.08.12 |
| Python 클래스 기초 (2) (6) | 2025.07.30 |
| Python 클래스 기초 (1) (4) | 2025.07.30 |