2025. 9. 14. 22:32ㆍ심화_인공지능 YOLO기반 부트캠프_일기(CNN)
PyTorch로 배우는 머신러닝: 이진 분류와 선형 회귀 완벽 가이드
머신러닝은 컴퓨터가 데이터를 보고 패턴을 찾아내는 기술입니다. 이 포스트에서는 PyTorch를 사용해 두 가지 문제를 해결합니다:
- 이진 분류: 데이터가 두 가지 중 하나(예: 참/거짓)에 속하는지 예측.
- 선형 회귀: 데이터로 숫자 값(예: 집값)을 예측.
대학생 이상을 위한 내용이지만, 초등학생도 이해할 수 있도록 쉽게 설명합니다. 코드에는 주석을 달아 각 줄의 기능과 변수를 명확히 했고, 추가로 정규화, .unsqueeze(1), 신경망 구조(nn.Linear), 검증의 필요성, 그리고 노드 수 변경(nn.Linear(2, 32))에 대한 질문도 포함했습니다.
1. 이진 분류: 두 가지를 구분하기
1.1 이진 분류란?
데이터를 보고 두 가지 중 하나를 선택하는 작업입니다. 예를 들어, 사진을 보고 "고양이인가, 강아지인가?"를 예측하는 것처럼요. 여기서는 가짜 데이터를 사용해 컴퓨터가 두 가지를 구분하도록 학습시킵니다.
1.2 코드: 컴퓨터가 두 가지를 배우는 과정
import torch # PyTorch 라이브러리: 머신러닝 계산 도구
import torch.nn as nn # 신경망 구성 요소
import torch.optim as optim # 뇌 최적화 도구
from sklearn.datasets import make_classification # 가짜 데이터 생성
from sklearn.model_selection import train_test_split # 데이터 나누기
from sklearn.preprocessing import StandardScaler # 숫자 크기 맞추기
import matplotlib.pyplot as plt # 그래프 그리기
# 가짜 데이터 만들기: 1000개 샘플, 2가지 특징(예: 귀 길이, 꼬리 모양), 두 가지로 분류(참/거짓)
X, y = make_classification(n_samples=1000, n_features=2, n_classes=2,
n_informative=2, n_redundant=0, random_state=0)
# X: 데이터(1000x2 배열, 각 행은 샘플, 열은 특징)
# y: 정답(참/거짓, 0 또는 1로 표시)
# 데이터 나누기: 학습용(80%), 검증용(20%)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# X_train: 학습 데이터, X_val: 검증 데이터
# y_train: 학습 정답, y_val: 검증 정답
# 숫자를 비슷한 크기로 맞추기(정규화: 평균 0, 표준편차 1)
scaler = StandardScaler() # 숫자 크기 조정 도구
X_train = scaler.fit_transform(X_train) # 학습 데이터 정규화
X_val = scaler.transform(X_val) # 검증 데이터 정규화(학습 데이터 기준 사용)
# 컴퓨터가 이해하도록 데이터 변환(PyTorch 텐서로)
X_train = torch.tensor(X_train, dtype=torch.float32) # 학습 데이터 텐서
y_train = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1) # 학습 정답 텐서, (N,) → (N,1)
X_val = torch.tensor(X_val, dtype=torch.float32) # 검증 데이터 텐서
y_val = torch.tensor(y_val, dtype=torch.float32).unsqueeze(1) # 검증 정답 텐서
# 컴퓨터 뇌(신경망) 만들기
model = nn.Sequential(
nn.Linear(2, 16), # 2가지 특징 입력, 16개 노드로 계산
nn.ReLU(), # 똑똑한 판단(음수는 0, 양수는 그대로)
nn.Linear(16, 1) # 16개 노드 → 최종 답(참/거짓)
) # model: 신경망 모델
# 오차 계산 방법과 뇌 최적화 도구
criterion = nn.BCEWithLogitsLoss() # 오차 계산 도구(참/거짓 예측 오차)
optimizer = optim.Adam(model.parameters(), lr=0.01) # 뇌 개선 도구(학습 속도 0.01)
# 100번 학습
epochs = 100 # 학습 반복 횟수
train_loss_history = [] # 학습 오차 기록
val_loss_history = [] # 검증 오차 기록
for epoch in range(epochs):
model.train() # 학습 모드 설정
optimizer.zero_grad() # 이전 계산 초기화
output = model(X_train) # 예측값 계산(순전파)
loss = criterion(output, y_train) # 예측과 정답 비교, 오차 계산
loss.backward() # 오차로 뇌 개선 방향 계산(역전파)
optimizer.step() # 뇌 업데이트
train_loss_history.append(loss.item()) # 오차 기록
model.eval() # 검증 모드 설정
with torch.no_grad(): # 계산 속도 높이기(역전파 안 함)
val_output = model(X_val) # 검증 데이터로 예측
val_loss = criterion(val_output, y_val) # 검증 오차 계산
val_loss_history.append(val_loss.item()) # 검증 오차 기록
if epoch % 10 == 0: # 10번마다 결과 출력
print(f"학습 {epoch}번: 학습 오차 = {loss.item():.4f}, 검증 오차 = {val_loss.item():.4f}")
# 오차 그래프 보기
plt.plot(train_loss_history, label='학습 오차') # 학습 오차 그래프
plt.plot(val_loss_history, label='검증 오차') # 검증 오차 그래프
plt.title("이진 분류 오차 그래프") # 그래프 제목
plt.xlabel("학습 횟수") # x축: 학습 횟수
plt.ylabel("오차") # y축: 오차 크기
plt.grid() # 격자 표시
plt.legend() # 범례 표시
plt.show() # 그래프 출력
# 정확도 확인
with torch.no_grad(): # 계산 속도 높이기
probs = torch.sigmoid(model(X_val)) # 예측값을 확률로 변환(0~1)
preds = (probs > 0.5).float() # 0.5 이상이면 참(1), 아니면 거짓(0)
acc = (preds == y_val).float().mean() # 예측과 정답 비교, 정확도 계산
print(f"검증 정확도: {acc.item()*100:.2f}%") # 정확도 출력
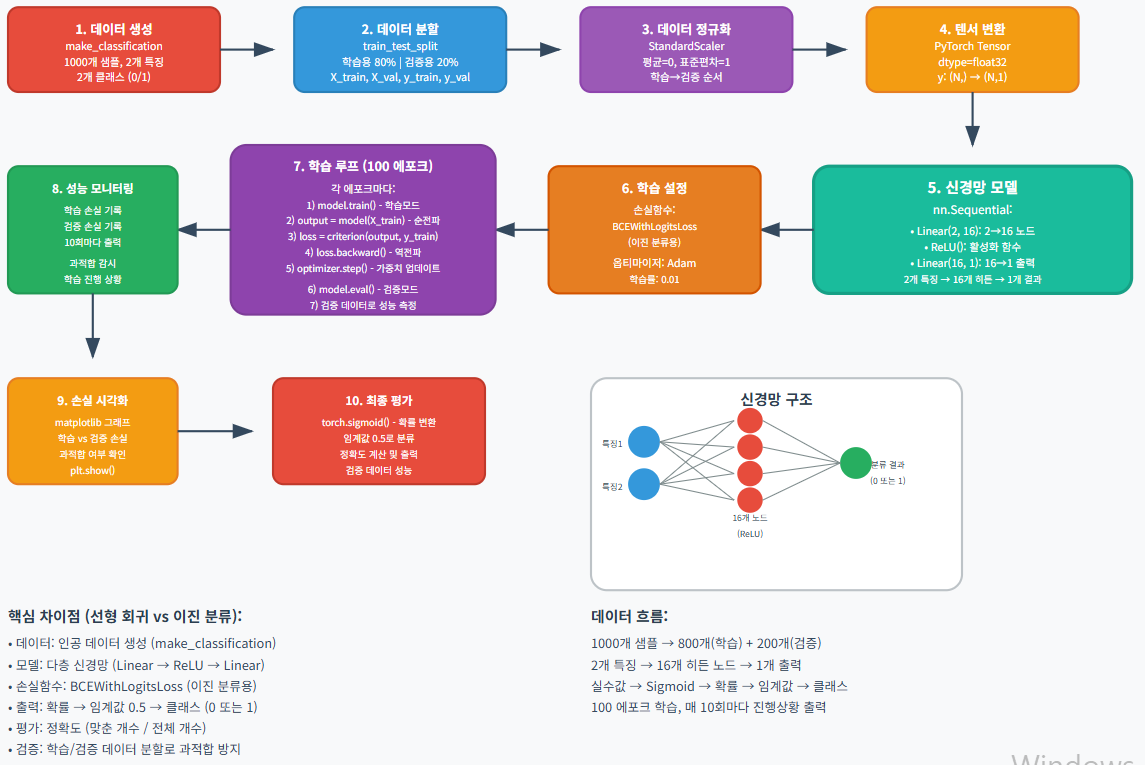
1.3 무슨 일이 일어났나?
- 데이터: 1000개의 가짜 데이터를 만들었어요. 각 데이터는 2가지 특징(예: 귀 길이, 꼬리 모양)을 가지며, 참/거짓(예: 고양이/강아지)로 나뉩니다.
- 준비: 데이터를 학습용(80%)과 검증용(20%)으로 나누고, 숫자를 비슷한 크기로 맞춥니다(정규화).
- 뇌 만들기: 신경망은 2가지 특징을 보고 16개의 생각을 거쳐 최종 답(참/거짓)을 냅니다.
- 학습: 100번 반복하며 예측하고, 오차를 줄이도록 뇌를 조정합니다.
- 순전파: 데이터를 보고 답을 예측(예: "고양이야!").
- 역전파: 오차를 보고 뇌를 개선(예: "틀렸어, 이렇게 고쳐!").
- 결과: 오차 그래프를 보고, 검증 데이터로 정확도를 확인(보통 90% 이상).
2. 선형 회귀: 집값 예측하기
2.1 선형 회귀란?
집의 정보(방 개수, 거주 인원, 집 나이)를 보고 집값을 예측하는 작업입니다. 예를 들어, "방이 5개인 집은 얼마일까?"를 알아맞힙니다.
2.2 코드: 컴퓨터가 집값을 배우는 과정
import torch # PyTorch 라이브러리: 머신러닝 계산 도구
import torch.nn as nn # 신경망 구성 요소
import pandas as pd # 데이터 파일 읽기
import matplotlib.pyplot as plt # 그래프 그리기
from sklearn.preprocessing import StandardScaler # 숫자 크기 맞추기
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 성능 평가 도구
import joblib # 숫자 변환 도구 저장/로드
# 데이터 불러오기: 캘리포니아 집 데이터
df = pd.read_csv("california_housing.csv") # CSV 파일 읽기
X = df[['AveRooms', 'AveOccup', 'HouseAge']].values # 입력: 방 개수, 거주 인원, 집 나이
y = df['MedHouseVal'].values # 출력: 집값
# 숫자를 비슷한 크기로 맞추기(정규화)
scaler_X = StandardScaler() # 입력 데이터 정규화 도구
scaler_y = StandardScaler() # 출력 데이터 정규화 도구
X = scaler_X.fit_transform(X) # 입력 데이터 정규화
y = scaler_y.fit_transform(y.reshape(-1, 1)) # 출력 데이터 정규화, (N,) → (N,1)
# 컴퓨터가 이해하도록 변환(PyTorch 텐서)
X_tensor = torch.tensor(X, dtype=torch.float32) # 입력 데이터 텐서
y_tensor = torch.tensor(y, dtype=torch.float32) # 출력 데이터 텐서
# 간단한 뇌 만들기: 선형 모델
model = nn.Linear(X_tensor.shape[1], 1) # 3가지 특징 입력 → 1개 출력(집값)
# 오차 계산 방법과 뇌 최적화 도구
criterion = nn.MSELoss() # 오차 계산 도구(예측값과 실제값 차이)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 뇌 개선 도구(학습 속도 0.01)
# 2000번 학습
epochs = 2000 # 학습 반복 횟수
losses = [] # 오차 기록
for epoch in range(epochs):
pred = model(X_tensor) # 집값 예측(순전파)
loss = criterion(pred, y_tensor) # 오차 계산
optimizer.zero_grad() # 이전 계산 초기화
loss.backward() # 오차로 뇌 개선 방향 계산(역전파)
optimizer.step() # 뇌 업데이트
losses.append(loss.item()) # 오차 기록
if (epoch + 1) % 200 == 0: # 200번마다 결과 출력
print(f"학습 {epoch+1}번, 오차: {loss.item():.4f}")
# 오차 그래프 보기
plt.plot(losses) # 오차 그래프
plt.xlabel("학습 횟수") # x축: 학습 횟수
plt.ylabel("오차") # y축: 오차 크기
plt.title("집값 예측 오차 그래프") # 그래프 제목
plt.grid(True) # 격자 표시
plt.show() # 그래프 출력
# 성능 확인
model.eval() # 검증 모드 설정
with torch.no_grad(): # 계산 속도 높이기
y_pred = model(X_tensor).numpy() # 예측값
y_true = y_tensor.numpy() # 실제값
y_pred_inv = scaler_y.inverse_transform(y_pred) # 예측값 원래 숫자로 복원
y_true_inv = scaler_y.inverse_transform(y_true) # 실제값 원래 숫자로 복원
mse = mean_squared_error(y_true_inv, y_pred_inv) # 평균 제곱 오차: 예측과 실제 차이
mae = mean_absolute_error(y_true_inv, y_pred_inv) # 평균 절대 오차: 절대값 차이
r2 = r2_score(y_true_inv, y_pred_inv) # 설명력: 모델이 데이터를 얼마나 잘 설명하는지
print(f"\n모델 성능:")
print(f"평균 제곱 오차: {mse:.4f}")
print(f"평균 절대 오차: {mae:.4f}")
print(f"설명력 점수: {r2:.4f}")
# 새 집값 예측
new_data = [[5.0, 3.0, 20.0]] # 새 데이터: 방 5개, 거주 3명, 집 나이 20년
new_data_scaled = scaler_X.transform(new_data) # 새 데이터 정규화
new_tensor = torch.tensor(new_data_scaled, dtype=torch.float32) # 텐서로 변환
with torch.no_grad():
prediction = model(new_tensor) # 집값 예측
pred_value = scaler_y.inverse_transform(prediction.numpy())[0][0] # 원래 숫자로 복원
print(f"예측된 집값: {pred_value:.3f} (단위: 10만 달러)")
# 뇌와 숫자 변환 도구 저장
torch.save(model.state_dict(), "linear_model.pth") # 뇌 저장
joblib.dump(scaler_X, "scaler_X.pkl") # 입력 변환 도구 저장
joblib.dump(scaler_y, "scaler_y.pkl") # 출력 변환 도구 저장
print("뇌와 변환 도구 저장 완료")
# 저장된 뇌로 예측
loaded_model = nn.Linear(3, 1) # 같은 구조의 새 뇌 만들기
loaded_model.load_state_dict(torch.load("linear_model.pth")) # 저장된 뇌 불러오기
loaded_model.eval() # 검증 모드 설정
scaler_X = joblib.load("scaler_X.pkl") # 입력 변환 도구 불러오기
scaler_y = joblib.load("scaler_y.pkl") # 출력 변환 도구 불러오기
new_data = [[4.0, 2.5, 15.0]] # 새 데이터: 방 4개, 거주 2.5명, 집 나이 15년
new_scaled = scaler_X.transform(new_data) # 새 데이터 정규화
new_tensor = torch.tensor(new_scaled, dtype=torch.float32) # 텐서로 변환
with torch.no_grad():
pred = loaded_model(new_tensor) # 집값 예측
pred_value = scaler_y.inverse_transform(pred.numpy())[0][0] # 원래 숫자로 복원
print(f"예측된 집값: {pred_value:.3f} (단위: 10만 달러)")
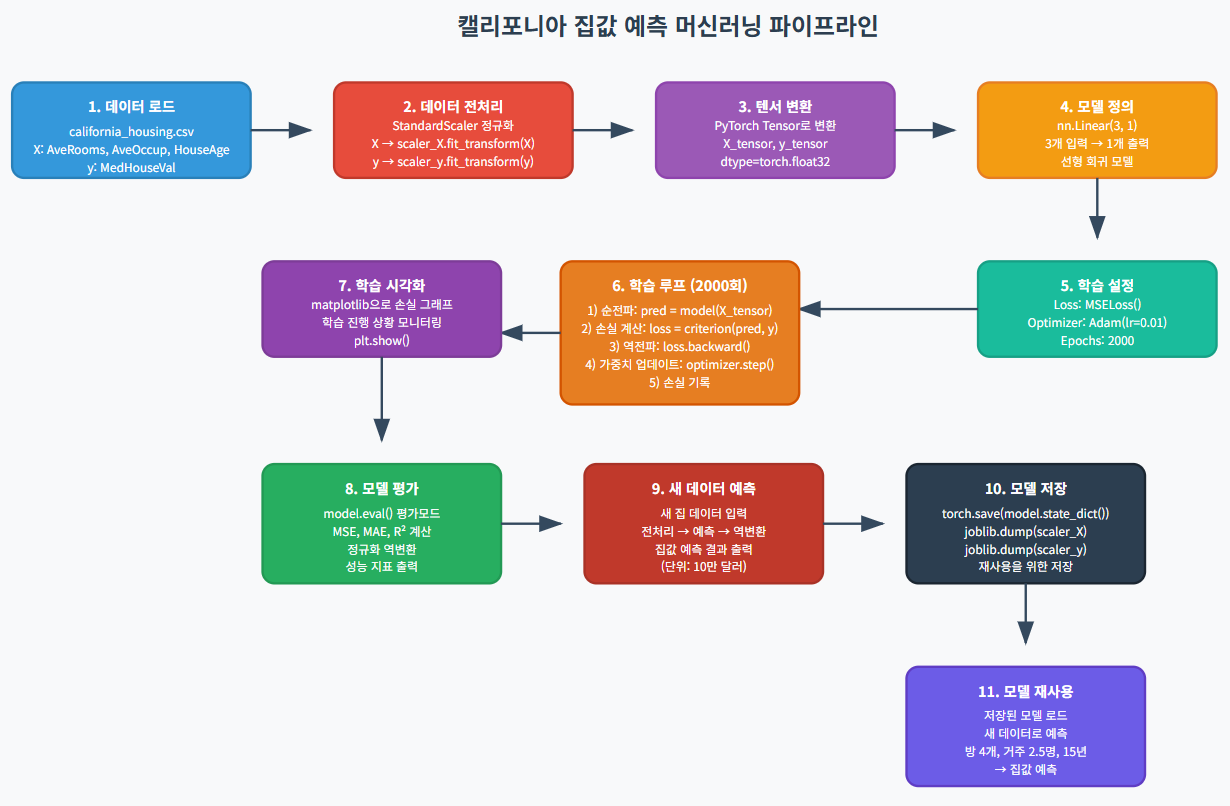
2.3 무슨 일이 일어났나?
- 데이터: 캘리포니아 집 데이터에서 방 개수, 거주 인원, 집 나이를 사용해 집값을 예측.
- 준비: 숫자를 비슷한 크기로 맞추고(정규화), 컴퓨터가 이해하도록 변환.
- 뇌 만들기: 간단한 선형 모델로 3가지 특징을 보고 집값을 예측.
- 학습: 2000번 반복하며 오차를 줄이도록 뇌를 조정.
- 순전파: 데이터를 보고 집값 예측.
- 역전파: 오차를 보고 뇌 개선.
- 성능: 오차 그래프와 점수(평균 제곱 오차, 평균 절대 오차, 설명력)를 확인.
- 예측: 새 집 정보로 집값 예측.
- 저장/불러오기: 뇌와 숫자 변환 도구를 저장하고, 나중에 불러와 예측.
3. 자주 묻는 질문들
3.1 정규화란 무엇이고 왜 하나?
- 정규화란?: 데이터 숫자를 비슷한 크기로 만드는 작업. 예: 집 크기(100
1000)와 집 나이(150)를 평균 0, 표준편차 1로 바꿔요. - 왜 하나?:
- 컴퓨터가 숫자 크기가 너무 다르면 헷갈려서 학습이 어려워요. 정규화하면 학습이 빠르고 안정적이에요.
- 큰 숫자 때문에 계산 오류(예: 숫자가 너무 커지는 문제)를 막아요.
- 코드에서: StandardScaler가 데이터를 정규화해 컴퓨터가 쉽게 배우도록 돕습니다.
3.2 .unsqueeze(1)은 왜 쓰나?
- 하는 일: 데이터 모양을 바꿔요. 예: y_train의 모양을 (N,)(1차원, [0, 1, 0])에서 (N, 1)(2차원, [[0], [1], [0]])로 바꿉니다.
- 왜 필요?: 신경망은 입력과 출력의 모양을 정확히 맞춰야 해요. 이진 분류 모델은 (N, 1) 모양의 출력을 기대하므로, 손실 함수(BCEWithLogitsLoss)가 제대로 작동하려면 이 모양이 필요해요.
- 비유: 책을 책장에 꽂으려면 책 크기가 책장 칸에 맞아야 하죠. .unsqueeze(1)는 데이터를 모델에 맞는 모양으로 정리하는 거예요.
3.3 nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 1)은 무슨 의미?
- nn.Linear(2, 16):
- 2개의 특징(예: 귀 길이, 꼬리 모양)을 받아 16개의 새로운 숫자를 만듭니다.
- 각 특징에 가중치를 곱하고 편향을 더해 16가지 관점을 만들어요.
- 비유: 2가지 재료(밀가루, 설탕)로 16가지 반죽을 만드는 것.
- 예시:
import torch import torch.nn as nn layer = nn.Linear(2, 16) # 2 입력 → 16 출력 input_data = torch.tensor([[3.5, 2.7]], dtype=torch.float32) # 입력: [귀 길이, 꼬리 모양] output = layer(input_data) # 출력: 16개 숫자 print("입력:", input_data) print("출력:", output)- 출력 예: tensor([[1.2345, -0.5678, ...]], grad_fn=<AddmmBackward0>)
- nn.ReLU():
- 16개 숫자 중 음수는 0으로, 양수는 그대로 둬요. 이렇게 하면 컴퓨터가 더 복잡한 패턴을 배울 수 있어요.
- 비유: 반죽을 구워서 나쁜 맛(음수)은 버리고 좋은 맛(양수)만 남기는 것.
- nn.Linear(16, 1):
- 16개의 숫자를 하나로 합쳐 최종 답(참/거짓)을 만듭니다.
- 비유: 16가지 반죽을 한 접시에 담아 "이건 맛있는 쿠키야!"라고 판단하는 것.
- 전체: 2개의 특징을 16개로 확장해 생각한 뒤, 하나로 요약해 참/거짓을 예측.
3.4 nn.Linear(2, 16)을 nn.Linear(2, 32)로 바꿀 수 있나?
- 답변: 네, 가능해요! nn.Linear(2, 32)는 2개의 특징을 받아 32개의 숫자를 만들어요. 다음 층도 nn.Linear(32, 1)로 바꿔야 모양이 맞아요.
- 차이:
- 16개 대신 32개 노드로 더 많은 관점을 만들어 더 깊게 생각할 수 있어요.
- 계산량이 늘어나지만, 복잡한 데이터라면 정확도가 올라갈 수 있어요.
- 단순한 데이터(이 코드의 가짜 데이터)라면 16개나 32개나 비슷할 수 있고, 과적합(학습 데이터만 잘 맞춤) 위험이 생길 수 있어요.
- 비유: 16가지 대신 32가지 반죽을 만들지만, 너무 많으면 낭비일 수도.
- 수정 코드:
model = nn.Sequential( nn.Linear(2, 32), # 2가지 특징 입력, 32개 노드로 계산 nn.ReLU(), # 똑똑한 판단 nn.Linear(32, 1) # 32개 노드 → 최종 답 )
3.5 왜 매번 학습 후 검증하나?
- 검증이란?: 학습한 모델이 새로운 데이터(검증 데이터)에서 얼마나 잘 작동하는지 확인하는 과정.
- 왜 매번?:
- 과적합 확인: 컴퓨터가 학습 데이터만 너무 잘 외워 새로운 데이터에 약해질 수 있어요(과적합). 검증 데이터를 보면 이를 빨리 알아차려요.
- 학습 점검: 학습 오차와 검증 오차를 비교해 모델이 잘 배우고 있는지 확인. 예: 학습 오차는 줄어도 검증 오차가 늘면 잘못된 방향으로 가고 있는 거예요.
- 비유: 공부 후 매번 시험을 쳐서 "이 공부법이 맞나?"를 확인하는 것. 연습 문제만 잘 풀면 소용없으니, 실제 시험 문제도 풀어보는 거예요.
- 코드에서: 매 에포크마다 val_loss를 계산해 학습 상태와 과적합 여부를 점검.
4. 순전파와 역전파: 컴퓨터가 배우는 방법
- 순전파: 데이터를 보고 답을 내는 과정. 예: 사진을 보고 "고양이!"라고 답하거나, 집 정보를 보고 "100만 달러!"라고 예측.
- 역전파: 틀린 답을 보고 뇌를 고치는 과정. 선생님이 "틀렸어, 이렇게 고쳐!"라고 알려주는 것처럼, 오차를 이용해 뇌를 업데이트.
마무리
이 포스트에서는 PyTorch로 두 가지 머신러닝 작업을 배웠습니다:
- 이진 분류: 가짜 데이터로 참/거짓을 예측(정확도 90% 이상 가능).
- 선형 회귀: 캘리포니아 집 데이터로 집값을 예측하고, 뇌를 저장/불러와 사용.
코드에 주석을 달아 각 줄이 하는 일을 알기 쉽게 했고, 자주 묻는 질문(정규화, .unsqueeze, 신경망 구조, 검증, 노드 수 변경)도 포함했습니다. 이 코드를 시작으로 더 복잡한 데이터나 뇌(예: 깊은 신경망)를 시도해보세요!
※이 포스트는 xAI의 Grok의 도움을 받아 작성되었습니다. Grok은 머신러닝 개념을 쉽게 이해할 수 있도록 설명과 예시를 제공해 주었습니다.
'심화_인공지능 YOLO기반 부트캠프_일기(CNN)' 카테고리의 다른 글
| 머신러닝 입문: PyTorch로 선형 데이터 예측해보기 (16) | 2025.08.18 |
|---|---|
| 딥러닝 초보를 위한 PyTorch 모델 학습 기록 (14) | 2025.08.14 |
| Pandas : 데이터프레임 기초부터 병합·결측치 처리·시각화까지 (12) | 2025.08.13 |
| 파이썬 고급 문법 정리 — 예외 처리, 제너레이터, 데코레이터까지,__call__ 메서드, 가변인자 덧셈 (6) | 2025.08.12 |
| Python 클래스 기초 (2) (6) | 2025.07.30 |